
引言:多层感知器(MLP)
- MLP 是我们最开始学习的神经网络模型结构,它具有输入层、多个隐藏层以及输出层,通过反向传播进行学习。
- 利用MLP的方式并不能处理所有问题,因为它没法辨别处理时序性的问题,,例如:当输入为[1, 2, 3] 希望输出4 ,而当输入[3, 2, 1] 时希望输出0 ,对于MLP来说,[1, 2, 3] 和 [3, 2, 1] 是相同的,因此无法得到预期的结果。
一、循环神经网络(RNN)
1、语言模型
语言模型:给定一句话前面的部分,预测接下来最有可能的一个词是什么。
(1)N-Gram 模型
预测横线处内容
我 昨天 上学 迟到 了,老师 批评 了 ___。
- 如果使用 2-Gram,电脑会在语料库中,搜索【了】后面最可能的一个词(显然不靠谱)。
- 如果使用 3-Gram,电脑会在语料库中,搜索【批评了】后面最可能的一个词(比上者靠谱,但远远不够,因为最关键的信息是【我】)。
(2)RNN
RNN 理论上可以往前看(往后看)任意多个单词。
2、循环神经网络
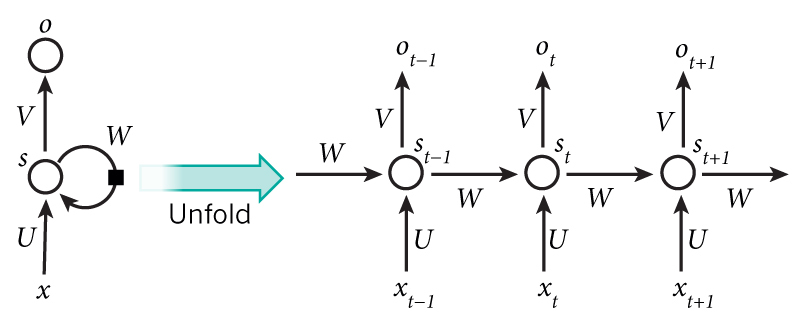
网络在 t 时刻接收到输入值 x_t 之后,隐藏层的值是 s_t,输出层的值是 o_t。可以用下面的公式来表示循环神经网络的计算方法: 式(1)是输出层的计算公式,输出层是一个全连接层,也就是它的每个节点都和隐藏层的每个节点相连。V是输出层的权重矩阵,g是激活函数。式(2)是隐藏层的计算公式,它是循环层。U是输入x的权重矩阵,W是上一次的值作为这一次的输入的权重矩阵,f是激活函数。
从上面可以看出,循环神经网络的输出值,是受前面历次输入值 $x_t$,$x_{t-1}$,$x_{t-2}$ $\cdots$影响的,这就是为什么循环神经网络可以往前看任意多个输入值的原因。
3、双向循环神经网络
对于语言模型来说,很多时候光看前面的词是不够的,比如:
预测横线处内容
我 的 手机 坏 了,我 打算____一部 新 手机。
可以想象,如果我们只看横线前面的词,手机坏了,那么我是打算修一修?换一部新的?还是大哭一场?这些都是无法确定的。但如果我们也看到了横线后面的词是『一部新手机』,那么,横线上的词填『买』的概率就大得多了。
在上一小节中的基本循环神经网络是无法对此进行建模的,因此,我们需要双向循环神经网络,如下图所示:
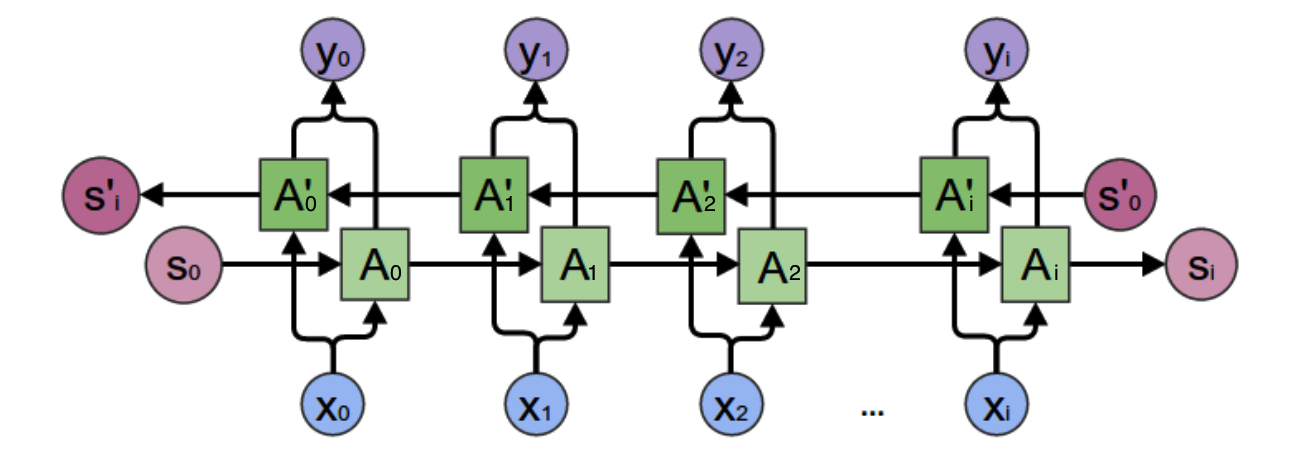
从上图可以看出,双向循环神经网络的隐藏层要保存两个值,一个 A_i 参与正向计算,另一个值 A’_i 参与反向计算。最终的输出值 $y_i$取决于$ A_i$ 和 $A’_i$。
其计算方法为:
从而,我们可以总结出双向循环神经网络的计算方法:
二、长短时记忆网络(LSTM)
LSTM 是 RNN 的一种,不同之处在于其有了更多的控制单元:input gate、output gate 以及 forget gate。
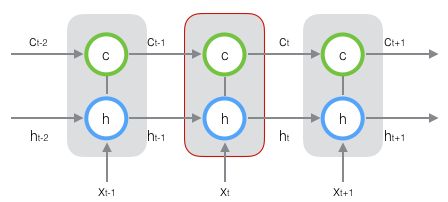
在t时刻,LSTM的输入有三个:当前时刻网络的输入值 $x_t$、上一时刻LSTM的输出值 $h_{t-1}$、以及上一时刻的单元状态 $c_{t-1}$;LSTM的输出有两个:当前时刻LSTM输出值 $h_t$、和当前时刻的单元状态 $c_t$。
LSTM的关键,就是怎样控制长期状态 c。在这里,LSTM的思路是使用三个控制开关。第一个开关,负责控制继续保存长期状态 c;第二个开关,负责控制把即时状态输入到长期状态 c;第三个开关,负责控制是否把长期状态 c 作为当前的LSTM的输出。