
一、MapReduce 原理
场景:150人的班级举行一次期末考试,老师想要统计每个分数有多少人,如何统计最高效?(PS:这门课有三个助教)
- 方法一:老师人特别好,不好意思麻烦助教,一个人哼哧哼哧统计完了,一个小时过去了。。。。
- 方法二:老师工作很忙,把任务分配给了助教,助教A统计、助教B记录、助教C负责扇风,50分钟过去了。。。。
- 方法三:老师工作很忙,把任务分配给了助教,助教们急着去吃饭,一人拿了50份就开始统计,20分钟后每个人手里都有一张纸记录了当前50份试卷的分数情况。助教A自告奋勇,拿着计算器加了加就得到了想要的结果,整个任务用时30分钟。
- 方法四:老师觉得助教也很辛苦,决定加入统计分数的战队中,于是每人只分配了40份不到的试卷,大概只要一刻钟所有人都有了统计的纸张。助教A再次自告奋勇,拿着计算器加了加就得到了想要的结果,整个任务用时25分钟。
- 方法五:让我们招募一些苦力。。。。。。
1、什么是MapReduce ?
- MapReduce 是一个基于 java 的并行分布式计算框架,它可以利用数据的位置,在存储的位置附近处理数据,以最大限度地减少通信开销。
- MapReduce合并了两种经典函数:
- 映射(Mapping)对集合里的每个目标应用同一个操作。即,如果你想把表单里每个单元格乘以二,那么把这个函数单独地应用在每个单元格上的操作就属于mapping。
- 化简(Reducing )遍历集合中的元素来返回一个综合的结果。即,输出表单里一列数字的和这个任务属于reducing。
- 分而治之
2、MapReduce流程
最简单的MapReduce应用程序至少包含 3 个部分:一个 Map 函数、一个 Reduce 函数和一个 main 函数。在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。main 函数将作业控制和文件输入/输出结合起来。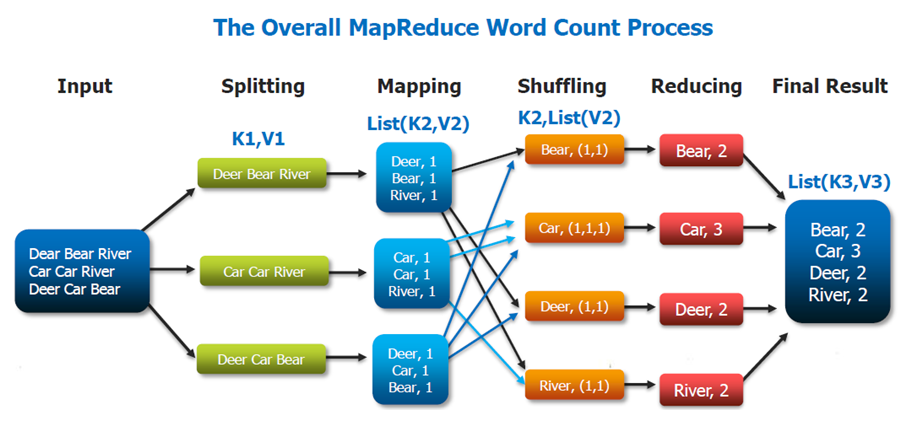
上图的流程大概分为以下几步:
- 假设一个文件有三行英文单词作为 MapReduce 的Input(输入),这里经过 Splitting过程把文件分割为3块。分割后的3块数据就可以并行处理,每一块交给一个 map 线程处理。
- 每个map线程中,以每个单词为key,以1作为词频数value,然后输出。
- 每个map的输出要经过shuffling(混洗),将相同的单词key放在一个桶里面,然后交给reduce处理。
- reduce接受到shuffle后的数据,会将相同的单词进行合并,得到每个单词的词频数,最后将统计好的每个单词的词频数作为输出结果。
上述就是 MapReduce 的大致流程,前两步可以看做map阶段,后两步可以看做reduce 阶段。
3、一些问题
Q1:Reduce步骤将一个类型的 key,送给同一个节点。比如说,把 Bear 都送给第一个节点、Car送给第二个节点。如何做到?
答:使用hash表的方式,一个key,放在hash表里面,就会产生一个为一个 code,然后再给它取余数。比如机器有四个节点,做 reduce,那么就取余4,这样计算的任务就分给四台机器。这个就是shuffl机制。(shuffl就是洗牌的意思)(这个算法其实就是哈希取模的算法)
Q2:map 执行完成之后,中间结果保存在哪里?
答:map函数输出的中间结果 key/value 数据在内存中进行缓存,然后周期性的写入磁盘。每个map函数在写入磁盘之前,通过哈希函数,将自己的 key/value 对分割成R份。(R是reduce的个数,哈希函数一般是用 key 对 r 进行哈希取模,这样将map函数的中间数据分割成 r 份,每一份分给一个 reduce)。当某个reduce任务的worker接收到master的通知,其通过rpc远程调用 将map任务产生的m份属于自己的文件远程拉取到本地。