
Spark 入门教程
引言:Hadoop
Hadoop 解决的问题:解决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的可靠存储和处理。
- HDFS:在普通 PC 组成的集群上提供高可靠的文件存储,通过将块保存多个副本的方法解决服务器或硬盘坏掉的问题。( Namenode 负责数据存储位置的记录,Datanode 负责数据的存储)
- MapReduce:通过简单的 Mapper 和 Reducer 的抽象提供一个编程模型,可以在一个由几十台上百台的 PC 组成的不可靠集群上并发地、分布式地处理大量的数据集,而把并发、分布式(如机器间通信)和故障恢复等计算细节隐藏起来。这样,复杂的数据处理可以分解为由多个 Job(包含一个 Mapper 和一个 Reducer)组成的有向无环图(DAG),然后每个 Mapper 和 Reducer 放到 Hadoop 集群上执行,就可以得出结果。
Hadoop 的局限和不足:
- 一个 Job 只有 Map 和 Reduce 两个阶段,复杂的计算需要大量的 Job 完成,Job 之间的依赖关系是由开发者自己管理的;
- 处理逻辑隐藏在代码细节中,没有整体逻辑;
- 中间结果也放在 HDFS 文件系统中;
- ReduceTask 需要等待所有 MapTask 都完成后才可以开始;
- 时延高,只适用 Batch 数据处理,对于交互式数据处理,实时数据处理的支持不够;
- 对于迭代式数据处理性能比较差。
一、Spark 简介
Spark 是一个依托于 Hadoop 生态的分布式内存计算框架,在吸收了 Hadoop MapReduce 优点的基础上提出以 RDD 数据表示模型,将中间数据放到内存,用于迭代运算,适用于实时计算、交互式计算场景。
1、Spark 解决了 MapReduce 中的哪些问题?
-
抽象层次低,需要手工编写代码来完成,使用上难以上手。
解决:通过 Spark 中的 RDD 来进行抽象
-
只提供两种操作,Map 和 Reduce,表达力欠缺
解决:在 Spark 中提供了多种算子
-
一个 Job 只有 Map 和 Reduce 两个阶段
解决:在 Spark 中可以有多个阶段(stage)
-
中间结果也放在 HDFS 文件系统中(速度慢)
解决:中间结果放在内存中,内存放不下了会写入本地磁盘,而不是 HDFS
-
延迟高,只适用 Batch 数据处理,对于交互式数据处理,实时数据处理的支持不够
解决:SparkSQL 和 SparkStreaming 解决了上述问题
-
对于迭代式数据处理性能比较差
解决:通过在内存中缓存数据,提高迭代式计算的性能
Spark 比 MapReduce 快的原因:
- Spark 基于内存迭代,而 MapReduce 基于磁盘迭代;
- DAG 计算模型在迭代计算上比 MR 更有效率。(DAGScheduler 是个改进版的 MapReduce);
- Spark 是粗粒度的资源调度,而 MR 是细粒度的资源调度。
2、RDD(Resilient Distributed Dataset )-弹性分布式数据集
RDD API 是 Spark 上处理数据的最基本编程方式。RDD 是 Spark 的核心,通过熟悉 RDD 编程,可以看出分布式数据集在 Spark 【多个节点】【分阶段】并行计算的实质。
-
什么是 RDD?——RDD 即弹性分布式数据集(Resilient Distributed Dataset),是 Spark 对数据的核心抽象,意味着在 Spark 上进行数据挖掘首先需要将待处理数据源转化成 RDD,在此 RDD 上进行操作。
-
什么叫数据的核心抽象?——即数据组织、处理基本单位。在 Spark 不引入高级模块时,对数据的所有操作不外乎创建 RDD、转化已有 RDD以及调用 RDD 操作(API)进行求值。
-
Spark 中的 RDD 就是一个不可变的分布式对象集合。每个 RDD 都被分为多个分区(Partitons),这些分区被分发到集群中的不同节点进行计算。
-
Spark 提供了 RDD 上的两类操作:转化和行动
转化操作会由一个 RDD 生成一个新的 RDD,例如 RDD 利用 map(func) 函数遍历并利用 func 处理每一个元素,进而生成一个新的 RDD 就是一个常见的转化操作。
行动操作会对 RDD 计算出一个结果,是向应用程序返回值,或向存储系统导出数据的那些操作,例如 count(返回 RDD 中的元素个数)、collect(返回 RDD 所有元素)、save(将 RDD 输出到存储系统)、take(n)(返回 RDD 前n个元素)。
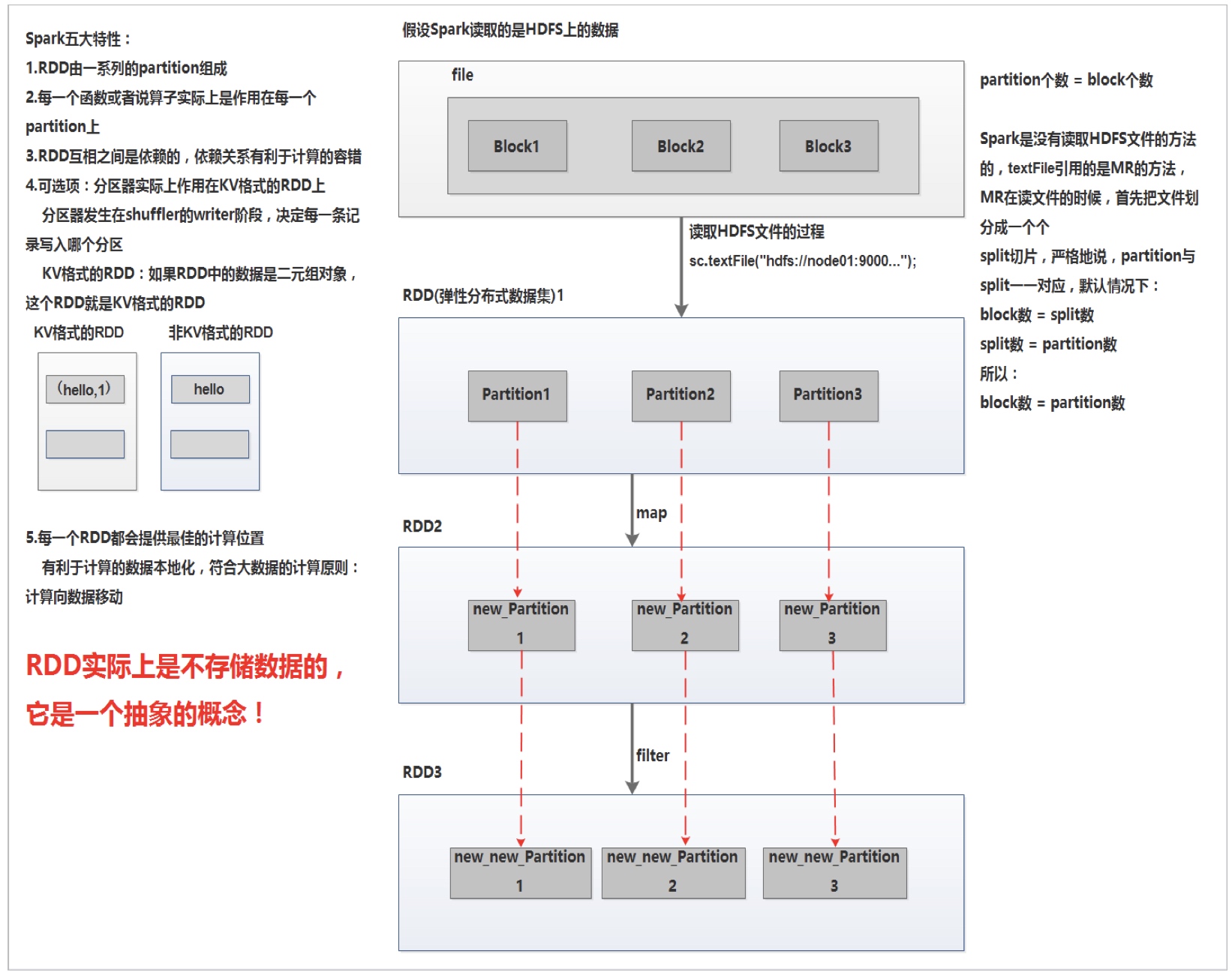
Spark 源码中 RDD 的定义:
- A list of partitions (它是一组分区,分区是 Spark 中数据集的最小单位)
- A function for computing each split (一个应用在各个分区上的计算任务)
- A list of dependencies on other RDDs (RDD之间的依赖关系,RDD 之间存在转化关系)
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) (一个计算分区的函数,spark 中支持基于 hash 的 hash 分区方法和基于范围的 range 分区方法)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file) (一个列表,存储的是每个分区优先存储的位置)
RDD 基本编程步骤:
Step1:读取内、外部数据源创建 RDD
Step2:使用诸如 map( )、filter( )这样的转化操作对 RDD 进行转化,以定义新的 RDD
Step3:对需要被重用的 RDD 手动执行 presist( )/cache( ) 操作
Step4:使用行动操作,例如 count( ) 和 first( ) 等,来触发一次并行计算,Spark 会对记录下来的 RDD 转化过程进行优化后再执行计算
3、DataFrame
Dataframe 的定义与 RDD 类似,都是 Spark 平台用以分布式并行计算的不可变分布式数据集合。与 RDD 最大的不同在于,RDD 仅仅是一条条数据的集合,并不了解每一条数据的内容是怎样的,而 DataFrame 明确了解每一条数据有几个命名字段组成,带有 schema 元信息,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型,使得 Spark SQL 得以洞察更多的结构信息,从而对藏于 DataFrame 背后的数据源以及作用于 DataFrame 之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。(在Java 和 Scala 中,DataFrame 其实就是 DataSet[Row],即由表示每一行内容的 Row 对象组成的 DataSet 对象。) 可以用下面一张图详细对比Dataframe和 RDD 的区别:
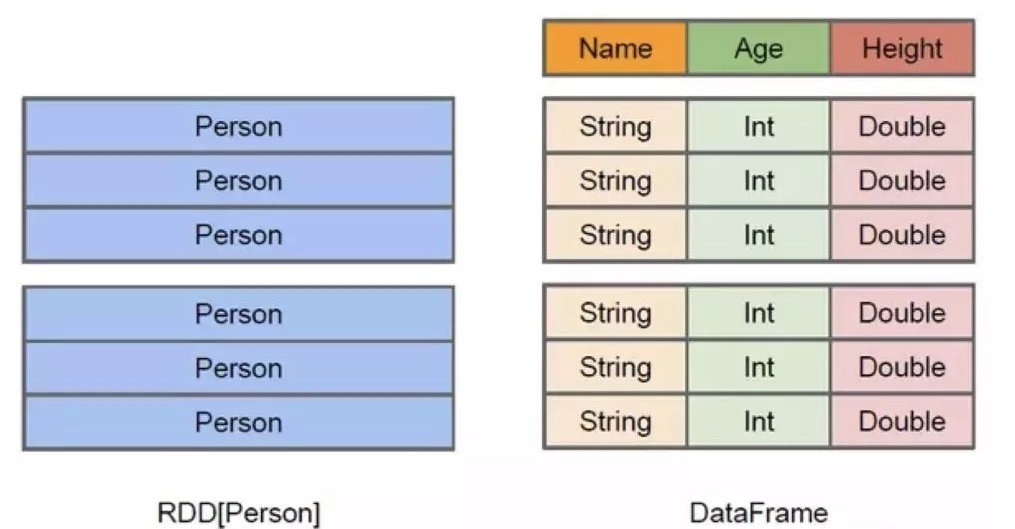
左侧的 RDD[Person] 虽然以 Person 为类型参数,但Spark框架本身不了解 Person 类的内部结构。而右侧的 DataFrame 却提供了详细的结构信息,使得 Spark SQL 可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。DataFrame多了数据的结构信息,即 schema。RDD 是分布式的 Java 对象的集合。DataFrame 是分布式的 Row 对象的集合。DataFrame 除了提供了比 RDD 更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化,比如 filter 下推、裁剪等。
二、RDD 简单实例—— wordcount
// scala 实现 wordcount 实例
// 首先借助 SparkContest 提供的 textFile 函数从 HDFS 读取要统计词频的文件,转化为记录着每一行内容的 RDD
val fileRDD = sc.textFile("hdfs://...") //此时的 RDD:表示每一行内容的字符串对象组成的集合
/*
* 1、.flatMap(line => line.split(" "))将每一行的单词按空格分隔,从而形成了记录着文本文件所有单词的 RDD
* 2、.map(word => (word,1))将上一步得到的记录着每一个单词的 RDD 转化为 (word,1)这种记录着每一个单词出现次数的键值对(key-value) RDD
* 3、采用reduceByKey(_+_)来按照键(key)将相同单词出现次数进行相加,进而求出每个词的词频
*/
val counts = fileRDD.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
// 最后通过.saveAsTextFile()函数将结果存入HDFS中
counts.saveAsTextFile("hdfs://...")
三、常见的转化操作和行动操作
(一)、基本 RDD 转化操作
1、map、filter
- map( ):接收一个函数,把这个函数用于 RDD 中的每个元素,将函数的返回结果作为结果 RDD 中对应元素的值
- filter( ):接收一个函数,并将 RDD 中满足该函数的元素放入新的 RDD 中返回
// 简单的 map 实例
var rdd1 = sc.parallelize(Array(3,4,8,5,6))
var rdd2 = rdd1.map(x => x*3).collect
// 结果:rdd2:Array[Int] = Array(9,12,24,15,18)
var rdd3 = rdd1.map(_*2).sortBy(x => x, true).collect()
// 结果:rdd3:Array[Int] = Array(6,8,10,12,16)
// 简单的 filter 实例
var rdd1 = sc.parallelize(List(3,4,99,5,6))
var rdd2 = rdd1.filter(_>50).collect
// 结果:rdd2:Array[Int] = Array(99)
var rdd3 = rdd1.filter(x => x>50).collect()
// 结果:rdd3:Array[Int] = Array(99)
var rdd4 = rdd1.filter(_%3 == 0).collect()
// 结果:rdd4:Array[Int] = Array(3,99,6)
2、flatMap
flatMap(func) 的传入 func 在处理每一个元素时,都可能会产生一个或多个对应的元素组成的返回值序列的迭代器
// flatMap 和 map 的区别
val rdd1 = sc.parallelize(List("coffee panda","happy panda","happiest panda party"))
val rdd2 = rdd1.map(x => x.split(" ")).collect
// 结果:Array[String] = Array([coffee, panda], [happy, panda], [happiest, panda, party])
val rdd3 = rdd1.flatMap(x => x.split(" ")).collect
// 结果:Array[String] = Array(coffee, panda, happy, panda, happiest, panda, party)
3、集合操作(distinct、union、intersection、subtract、cartesian)
- 去重(distinct)
- 合并(union)
- 相交(intersection)
- 做差(subtract)
- 笛卡尔积(cartesian)
(二)、基本 RDD 行动操作
- first( ):返回数据集中的第一个元素(类似于take(1))。
- take(n):返回数据集中的前n个元素。
- takeOrdered(n, [ordering]):返回RDD按自然顺序或自定义顺序排序后的前n个元素。
- takeSample(withReplacement,num,seed):用于从数据集中采样,从RDD随机返回一些元素,以数组形式返回,可通过参数num控制样本元素个数。
- collect( ):将RDD中的所有元素以数组的形式返回到驱动程序中。通常在调用了filter或者其他方法返回了一个足够小的RDD时使用。
- count( ):返回数据集中元素的个数。
- countByValue( ):统计RDD中各元素出现次数,返回的(元素值,出现次数)键值对的map。
- reduce(func):reduce将RDD中元素两两传递给输入函数,同时产生一个新的值,新产生的值与RDD中下一个元素再被传递给输入函数直到最后只有一个值为止。这个函数应该符合结合律和交换律,这样才能保证数据集中各个元素计算的正确性。foreach(func):对数据集中每个元素使用函数func进行处理。该操作通常用于更新一个外部累加器(Accumulator)或与外部数据源进行交互。
- saveAsTextFile(path):将数据集中的元素以文本文件(或文本文件集合)的形式保存到指定的本地文件系统、HDFS或其他Hadoop支持的文件系统中。Spark将在每个元素上调用toString方法,将数据元素转换为文本文件中的一行记录。saveAsSequenceFile(path) (Java and Scala):将数据集中的元素以Hadoop Sequence文件的形式保存到指定的本地文件系统、HDFS或其他Hadoop支持的文件系统中。该操作只支持对实现了Hadoop的Writable接口的键值对RDD进行操作。在Scala中,还支持隐式转换为Writable的类型(Spark包括了基本类型的转换,例如Int、Double、String等)。
- saveAsObjectFile(path) (Java and Scala):将数据集中的元素以简单的Java序列化的格式写入指定的路径。这些保存该数据的文件可以使用SparkContext.objectFile()进行加载。
// 行动操作示例
val rdd1 = sc.parallelize(List(5,3,2,4,1))
rdd1.first()
// 结果:Int = 5
rdd1.take(2)
// 结果:Array[Int] = Array(5,3)
rdd1.takeOrdered(2)
// 结果:Array[Int] = Array(1,2)
val rdd2 = rdd1.collect()
// 结果:Array[Int] = Array(5,3,2,4,1)
rdd1.count()
// 结果:Long = 5
val rdd3 = rdd1.reduce(_+_)
// 结果:Int = 15
rdd1.foreach(println)
// 结果:
// 4
// 1
// 3
// 2
// 5
四、Spark SQL 指南
1、 pom.xml 的配置
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.dianping.poi</groupId>
<artifactId>poi-nlp-spark</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<description>spark project from archetype</description>
<properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.tools.version>2.10</scala.tools.version>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.1</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<!-- <dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Test -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs2</groupId>
<artifactId>specs2_${scala.tools.version}</artifactId>
<version>1.13</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.scalatest</groupId>
<artifactId>scalatest_${scala.tools.version}</artifactId>
<version>2.0.M6-SNAP8</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<!-- see http://davidb.github.com/scala-maven-plugin -->
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.13</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
</plugins>
</build>
</project>
2、Spark1.x中Spark SQL的入口点:HiveContext
package com.data.spark
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext}
/**
* HiveContext的使用
* 使用时需要通过--jars 把mysql的驱动传递到classpath
*/
object HiveContext {
def main(args: Array[String]) {
//1)创建相应的Context
val sparkConf = new SparkConf()
//在测试或者生产中,AppName和Master我们是通过脚本进行指定
sparkConf.setAppName("HiveContextApp").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
val hiveContext = new HiveContext(sc)
//2)相关的处理:
hiveContext.table("emp").show
//3)关闭资源
sc.stop()
}
}
3、Spark2.x中Spark SQL的入口点:SparkSession
package com.data.spark
import org.apache.spark.sql.SparkSession
/*
* SparkSession的使用
* */
object SparkSessionApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("SparkSession")
.config("spark.some.config.option", "some-value")
.getOrCreate()
val people = spark.read.json("file:///Users/yinchuchu/Downloads/software/hadoop/spark-2.2.0-bin-2.6.0-cdh5.7.0/examples/src/main/resources/people.json")
people.show()
spark.stop()
}
}
4、Spark SQL 编程
常用 spark 操作函数:
- .cache( ):缓存
- .filter( ):选择 (不会改变已有的 RDD 中的数据,而是返回一个全新的 RDD)
- .flatMap( ):一对一映射
- .map( ):多对一映射
- .count( ):计数
- .contains( ):是否包含,常与 .filter( ) 组合使用
- .split( ):根据括号内的符号进行分隔
- .collect( ):返回RDD中的元素
- .union( ):合并两个 RDD
- .take(n):取 RDD 前 n 个元素
- .foreach(func):对每个元素进行相同 func 操作
- .reduce((x,y) => x + y):参数 (func) 需要操作两个RDD元素类型的数据并返回一个同样类型的新元素
- .reduceByKey(+):操作键值对,根据 key 进行 value 的相加